Wavoice: A Noise-resistant Multi-modal Speech Recognition System Fusing mmWave and Audio Signals (SIGMOBILE Research Highlights, Best Paper Award Nomination)
(SIGMOBILE Research Highlights, Best Paper Award Nomination)
Abstract
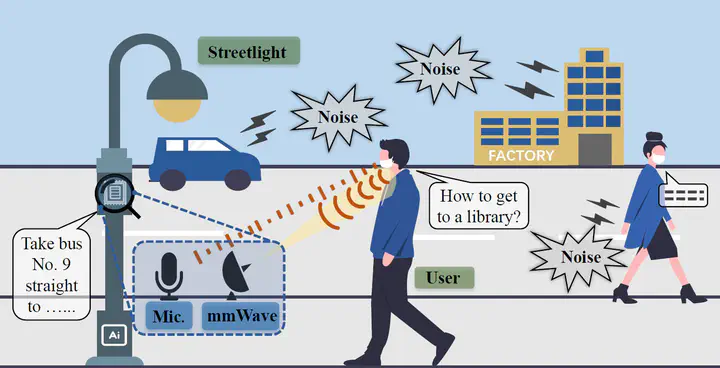
With the advance in automatic speech recognition, voice user interface has gained popularity recently. Since the COVID-19 pandemic, VUI is increasingly preferred in online communication due to its non-contact. Additionally, various ambient noise impedes the public applications of voice user interfaces due to the requirement of audio-only speech recognition methods for a high signal-to-noise ratio. In this paper, we present Wavoice, the first noise-resistant multi-modal speech recognition system that fuses two distinct voice sensing modalities, i.e., millimeter-wave (mmWave) signals and audio signals from a microphone, together. One key contribution is that we model the inherent correlation between mmWave and audio signals. Based on it, Wavoice facilitates the real-time noise-resistant voice activity detection and user targeting from multiple speakers. Furthermore, we elaborate on two novel modules into the neural attention mechanism for multi-modal signals fusion, and result in accurate speech recognition. Extensive experiments verify Wavoice’s effectiveness under various conditions with the character recognition error rate below 1% in a range of 7 meters. Wavoice outperforms existing audio-only speech recognition methods with lower character error rate and word error rate. The evaluation in complex scenes validates the robustness of Wavoice.